

Understanding how Apollo Cache normalizes data


Apollo uses a cache layer for its queries. By default, before executing a query, first the cache is accessed and if its not present in the cache then it makes a network call. This is called the cache-first fetch policy. You can find other fetch policies here.
Before storing the data in memory, Apollo InMemoryCache processes the data using a technique called normalization. In this article we would look at what normalization means and what it means in the context of Apollo and GraphQL.
What is normalization anyway?
Normalization is an approach of eliminating data redundancy. It is an approach to make sure that there is only 1 record of 1 data. It is a concept originally from databases and is being ported to frontend. normalizr was the first library that popularized using normalization for data management in frontend. It was used mostly with redux. Now it is also being used in Apollo with InMemoryCache.
Let us try looking at an example to understand what is normalization better. Consider a query Product in an e-commerce site that has the fields name, seller and brand.
This would look like this in a table
| id | name | seller | brand |
| 1 | iPhone 12 | T-Mobile | Apple |
| 2 | Cheetos | SnackCompany | Lay's |
| 3 | Apple Watch 6 | AccessoryBar | Apple |
| 4 | Galaxy S | T-Mobile | Samsung |
As we can see here that the seller T-Mobile and brand Apple are being repeated.
Having these duplicate instances of the same data can lead to the following problems:
- Suppose each seller has a verified status next to their account. And for products with verified sellers we show an icon next to it. If for example
T-Mobilebecame a verified seller. Then we would need to update all the products with this information. This is also called Updation anomaly - By normalizing data and preventing redundancy, we save a lot of memory space. If your app is being server side rendered, this would also mean fewer bytes transferred over the network.
We can prevent this duplication by having only a reference to the seller/brand. This would look like the following in a table. Instead of storing duplicates of the same data, we just store a reference to the data. In databases this concept is called foreign keys.
| id | name | seller | brand |
| 1 | iPhone 12 | seller#17 | brand#13 |
| 2 | Cheetos | seller#21 | brand#45 |
| 3 | Apple Watch 6 | seller#64 | brand#13 |
| 4 | Galaxy S | seller#17 | brand#15 |
Normalization in apollo
Let us now see how this looks like in apollo. If we want to fetch products we would have a query like this:
Product {
id
name
seller {
id
name
}
brand {
id
name
}
}
When we fetch this data, the contents of InMemoryCache looks like this: (Apollo DevTools: Firefox | Chrome)
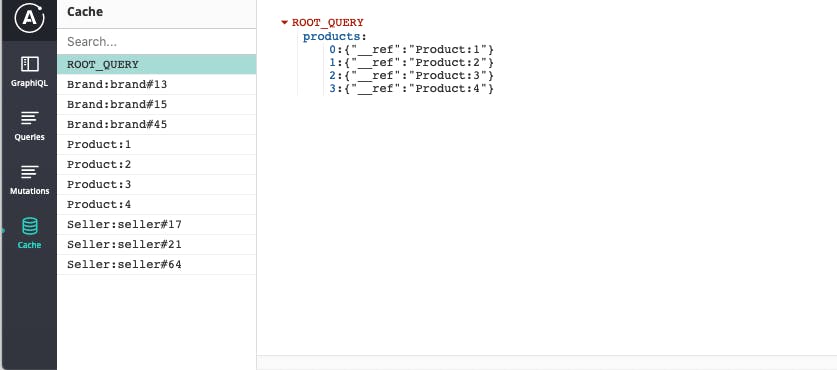
In the above image you can see how apollo cache stores the query data it receives internally. The cache has an entry for each Product. It also makes a separate entry for each Seller and Brand.
Note at the root level, it has a reference to all the products. Not the actual product itself.
This is how the Product, Seller and Brand look like



Note how the Product has a reference to Seller and Brand.
Now if any information about a Seller or Brand is updated; it is automatically available to all queries that are using it. This is the benefit of normalization since there are no duplicate references of the same data.
Caveat
This only works if you query for the id of Seller and Brand. Consider you query for the data like this without ids:
Product {
name
seller {
name
}
brand {
name
}
}
For the above query notice how the data is not normalized. You can see how each there is only a ROOT_QUERY and all data are stored in a large JSON.

What to do if id is not present?
You should always try to query an id if it is available in the server. You can try enforcing it by using graphql/required-fields eslint rule.
It can happen that your server doesn't send a unique id for a field or it sends it with a different name. In that case always try to first see if an id can be first sent from the server. If this is not possible, you can generate one on the client side by customizing identifier generation by type. You can use a field with a different name than the default id or _id. You can also generate the identifiers using 1 or more fields. If you want to know how to do this at runtime check out my other article on defining type policies during runtime in apollo
Conclusion
I hope you got a better idea about how apollo cache works under the hood, what is normalization and why it is useful. You can use apollo dev tools to make sure that the data you are fetching in your application is normalized. If it is not, you only have to make sure that the fields have a unique id field. For more information check out the references below